
Hello, I’m back! I know, I know, my last blog was from exactly 3 years ago. But it’s never too late right?
Streaming has always been an area that I was interested in, but I’ve never used it too much in the past. Today is the day! Let’s set up Kafka step by step, and make a program to print out some hashtags that are being mentioned on Twitter, right now.

![]()
![]()
Heads-up: I’m a Mac user, and am only running this program locally. The learning goal is to understand the work flow for Kafka and streaming project, not to get a scalable solution for some big data analysis.
Full source code: https://github.com/funjo/kafka_twitter_stream
Step 1: Install Kafka
I installed it through homebrew. You can also download the source code if you prefer.
fangzhou$ brew install kafka
Step 2: Start the server
From the homebrew installation, I got the following message. Apparently Kafka uses ZooKeeper server so you have to first start ZooKeeper then Kafka. I used the one command brew suggested.
==> Caveats
==> zookeeper
To have launchd start zookeeper now and restart at login:
brew services start zookeeper
Or, if you don’t want/need a background service you can just run:
zkServer start
==> kafka
To have launchd start kafka now and restart at login:
brew services start kafka
Or, if you don’t want/need a background service you can just run:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
fangzhou$zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
Step 3. Create a topic
fangzhou$ kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
To make sure the topic is created successfully, do a list command.
fangzhou$ kafka-topics --list --zookeeper localhost:2181
To delete the existing topic:
fangzhou$ kafka-topics --zookeeper localhost:2181 --delete --topic test
Step 4. (Optional) Send some messages
This step is not essential to this project, since we will not be sending messages to the Kafka producer ourselves (Twitter streaming API will). But just for the fun of it, you can try using the Kafka built-in command line client to send some messages to the Kafka cluster. Here is what I did:
One-off piece: I had to add two lines to the properties file (/usr/local/etc/kafka/server.properties) to make sure the port is correctly set otherwise the program will give me this error: {test=LEADER_NOT_AVAILABLE}.
port = 9092 advertised.host.name = localhost
After editing the properties file, you need to restart the kafka server repeating Step 1. Then the following should work:
fangzhou$ kafka-console-producer --broker-list localhost:9092 --topic test >Hello >It's me >I was wondering if after all these years you'd like to meet >:p
Open another shell tab:
fangzhou$ kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning Hello It's me I was wondering if after all these years you'd like to meet :p
If you keep sending messages to the Producer, the Consumer will also keep printing out your input in real time. Fun! Isn’t it? Finally we can talk to ourselves programmatically now.
Step 5. Create a Java Maven project and set up the pom.xml file
Code in Xml has some display problem on this site, please check out in my repo instead: https://github.com/funjo/kafka_twitter_stream/blob/master/pom.xml
Step 6. Create a class using KafkaProducer class
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.ConfigurationBuilder;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* A Kafka Producer that gets tweets on certain keywords from twitter datasource and publishes to a kafka topic
*
* Arguments: ...
* - Twitter consumer key
* - Twitter consumer secret
* - Twitter access token
* - Twitter access token secret
* - The kafka topic to subscribe to
* - The keyword to filter tweets
* - Any number of keywords to filter tweets
*
* Original source: https://stdatalabs.com/2016/09/spark-streaming-part-3-real-time/
* Modified by: Fangzhou Cheng
*/
public class kafkaTwitterStream {
public static void main(String[] args) throws Exception {
final LinkedBlockingQueue queue = new LinkedBlockingQueue(1000);
if (args.length < 4) {
System.out.println(
"Usage: KafkaTwitterProducer ");
return;
}
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String topicName = args[4];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
// Set twitter oAuth tokens in the configuration
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true).setOAuthConsumerKey(consumerKey).setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken).setOAuthAccessTokenSecret(accessTokenSecret);
// Create twitterstream using the configuration
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletionNotice) {
System.out.println("Got a status deletion notice id:" + statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
System.out.println("Got track limitation notice:" + numberOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
System.out.println("Got scrub_geo event userId:" + userId + "upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
// Filter keywords
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
// Add Kafka producer config settings
Properties props = new Properties();
props.put("metadata.broker.list", "localhost:9092");
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer(props);
int i = 0;
// poll for new tweets in the queue. If new tweets are added, send them to the topic
while (true) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
} else {
for (HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord(topicName, Integer.toString(i++), ret.getText()));
}
}
}
}
}
Step 7. Compile and run the java application
If you don’t have Maven installed yet, you should also get one. I also installed it from homebrew by running command `brew install maven`.
To run the application, you’ll also need your Twitter consumer key and secret, access token and secret. If you don’t have one, go apply for a new one here https://dev.twitter.com/apps/new. In my case, I’ve already applied for an app before with my other projects so I’ll just use it ;).
fangzhou$ mvn compile fangzhou$ mvn exec:java -Dexec.mainClass=kafkaTwitterStream -Dexec.args="twitter-consumer-key twitter-consumer-secret twitter-access-token twitter-access-token-secret topic-name twitter-search-keywords"
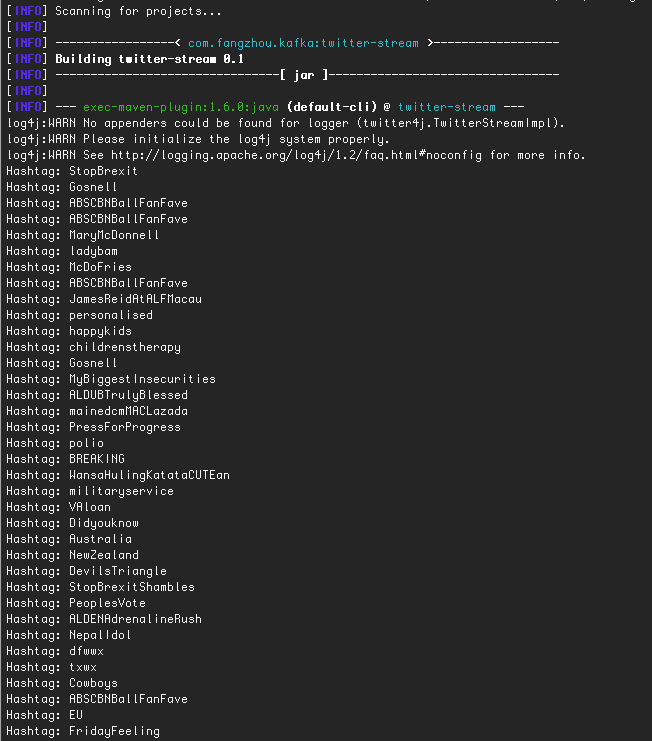
Step 8. Enjoy watching the live result
For example, this is probably 2 seconds’ results for Twitter on September 21, 2018 with search keyword “theresa may”:

Hi, Fangzhou. I’m Dennis, graduated from NYU last year. 🙂
LikeLike